RoleSolo builder
Product · Engineering
✦ Case study·AI Pipeline
SoloEmail-to-Wardrobe pipeline.
An AI pipeline that pulls 13 years of fashion purchases from Gmail into a digital wardrobe. 1,191 emails. $1.29 total cost. 102 items found.
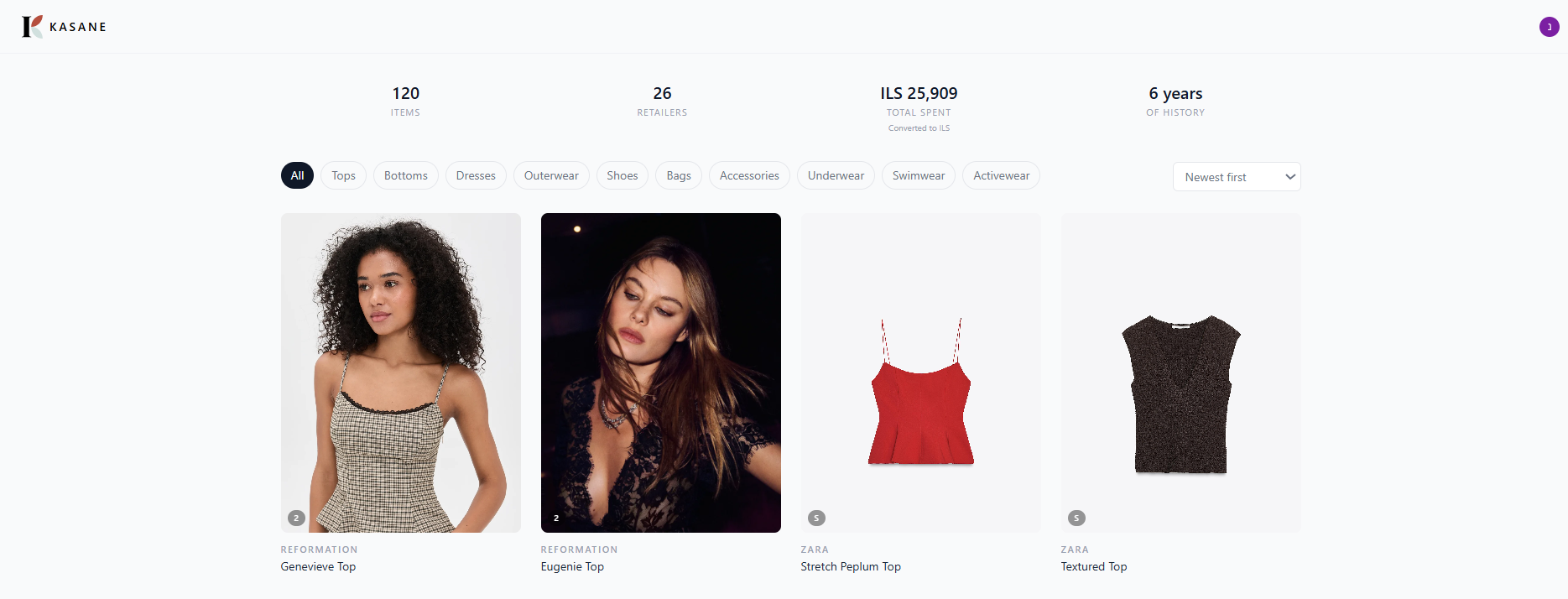 Kasane · Wardrobe view
Kasane · Wardrobe viewThe realization
“I didn't know what I owned.”
During the war, I was stuck at home, reorganizing my closet, and I had this realization: I didn't know what I owned. What I paid, when I bought things, whether I'd actually worn them.
The numbers backed it up. 53 items purchased per year on average, 4x more than in 2000. 40% never worn. ~100 hours a year spent in wardrobe panic.
Every closet app on the market (Whering, Acloset, Cladwell, Alta) requires you to photograph every item before you get any value. Nobody finishes that.
But receipts already live in email. And after COVID, even physical stores started pushing emailed receipts. The coverage is there now in a way it wasn't a few years ago.
I wanted to know if that signal alone could build the closet, without the photo grind.
The product
“Connect Gmail, wait 3 minutes, see your wardrobe.”
You sign in with Google. The system searches your inbox, filters out noise, sends real purchase emails to Claude for extraction, saves the results.
You get a browsable wardrobe: brand, category, size, color, price, order date, product images. Purchases come in four currencies. Prices are stored as-is and converted at display time with cached exchange rates, so you can see total spend in ILS even if you bought from Revolve in USD and ASOS in GBP.
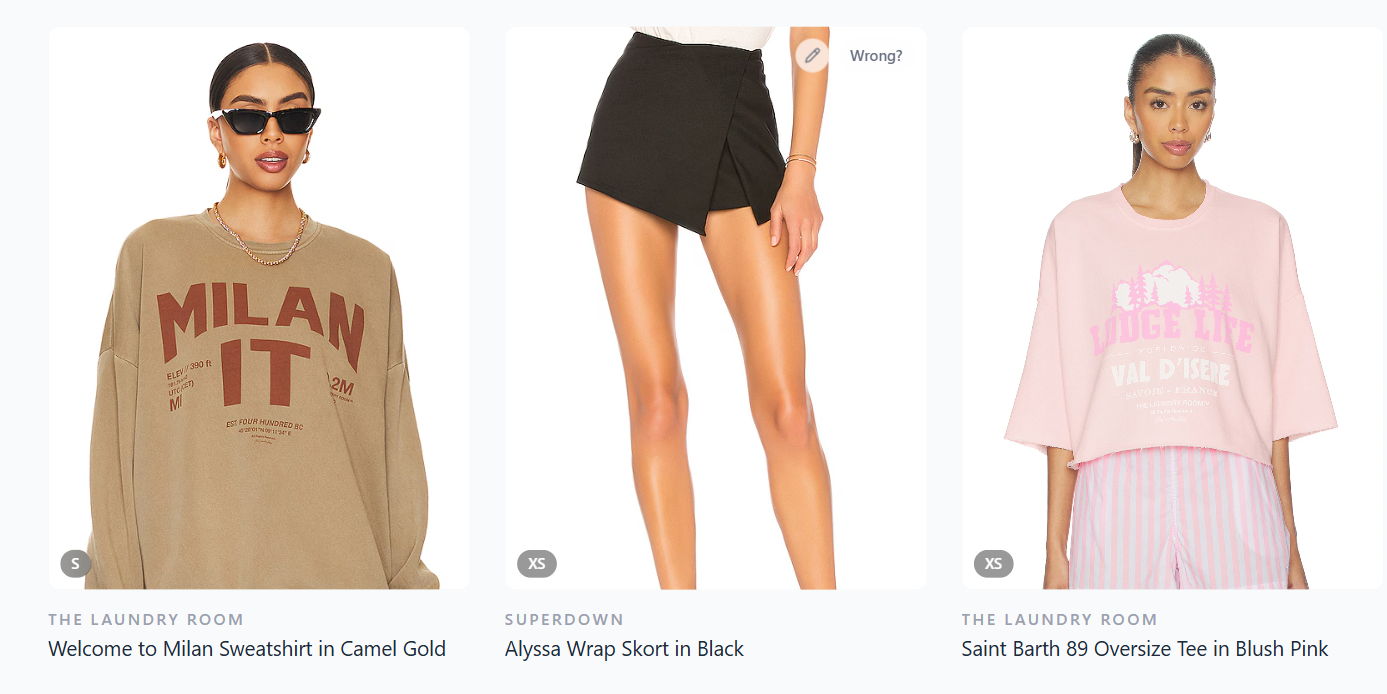
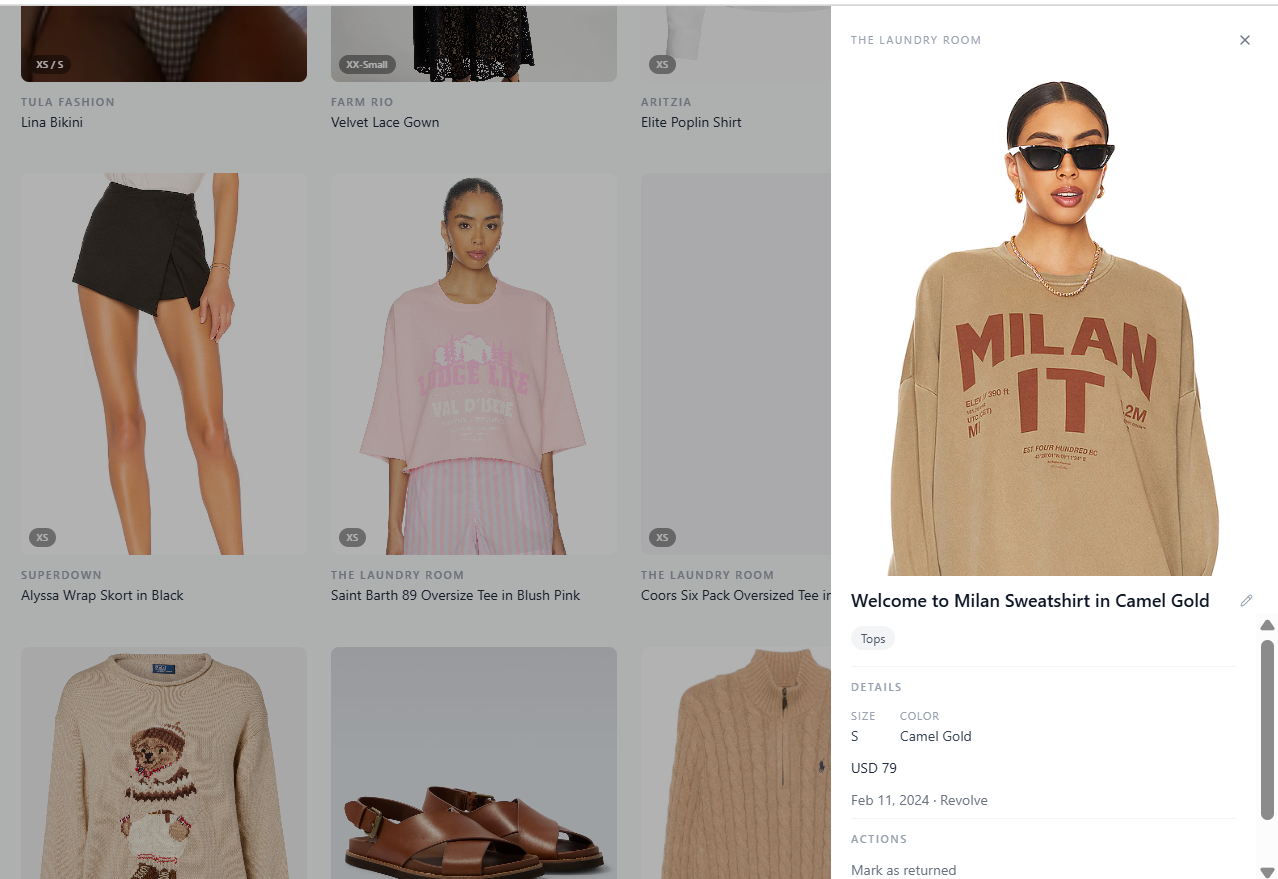
How it works
“Make AI the last resort, not the first pass.”
Claude is the expensive step. It should only see emails that have a real chance of being fashion purchases. The entire pipeline is designed around that constraint.
Pipeline architecture4 stages · 1 AI call
01
Gmail Search
6 parallel queries: label:purchases, Shopify, Global-e, exact phrases, Hebrew, receipts.
FREE
02
Subject Pre-filter
Regex on subject + sender, blocks shipping noise, subscriptions, promos.
FREE
03
Body Decode + Platform Handlers
MIME decode, HTML strip, 12k cap, Wolt/Amazon snippet check.
FREE
04
Claude Haiku
Structured JSON extraction, fashion / non-fashion classification.
~$0.006/email
| fetched | blocked (free) | reached Claude | fashion found | total cost | per item | retailers |
|---|---|---|---|---|---|---|
| 1,191 | 80.5% | 232 | 102 | $1.29 | $0.01 | 26 |
Funnel · 1,191 → 102 fashion items
Fetched
100%
Blocked (free)
80.5%
Reached Claude
19.5%
Fashion saved
8.6%
Non-fashion skipped
15.1%
What broke
“80% of my AI budget was going to dentist bills.”
The first version was an empty table and a PARSE button. I loaded 50 emails and immediately hit the first problem: Temu alone generated 10+ emails per order, all noise. I cut it. Get signal from the easy retailers first.
Then patterns started showing up. Small indie brands were invisible because they all send through Shopify. One query addition caught Tiger Mist, Free People, Reformation, Sugarfree. International brands route through Global-e. The search strategy shifted from “list retailers” to “find platforms.”
After the first full scan, I ran a cost analysis. 80% of Claude calls were wasted. Not on expected noise, but on things I wouldn't have predicted: medical bills from Israeli invoicing platforms (morning.co, ezcount), courier updates, Hebrew parking confirmations matching as order signals because “אישור הזמנה” means both “order confirmation” and “reservation confirmation.”
I traced every wasted call to specific senders, simulated fixes, deployed the ones that cut cost without losing fashion items.
The principle: sample real data before building assumptions. The next version of the filter won't be a list of patterns I maintain by hand. It'll learn from its own scan history, auto-blocking senders with 0% fashion rate.
Identity
Kasane 重ね
The product would work fine as “Gmail Closet Scanner.” But I named it Kasane, Japanese for “to layer,” from the art of layering kimono fabrics in deliberate color harmonies.
Picked a terracotta and sage palette because it should feel like a closet, not a dashboard. Chose an editorial serif. Designed a logo with two leaves meeting at the stem of the K: one for raw input, one for refined output.
Wordmark
Kasane
重ね
Japanese: to layer
Palette
Earthy Red
#B54F3E
Pale Mint
#D1E0DE
Black
#000000
White
#FFFFFF
Platinum
#F4F4F5
Typography · Editorial serif
A closet, not a dashboard.
Aa Bb Cc · 0123456789 · 重ね